|
1993��9�£�һ����ΪNCSA Mosaic���������ʽ֧������ҳ��Ƕ��ͼƬ�����־�Ż������Ӵ��ı�ʱ��������“��ͼ������”�Ķ�ý��ʱ����������Ż��������������������ƶ��豸���ռ�����Ϣ�Ļ�ȡ;���ʹ���;��Ҳ���������ӣ���Ƶ��Ϊ��������ý�����ѵ���Ҫ��ɲ��֡�
�Ӵ�ͳ����Ƶ������վ�����ӵ�Ӱ��Ŀ�����绯���ٵ��������˵���Ƶֱ����վ��С��Ƶ������վ����������Ƶ�Ѿ������˱�ըʽ��չ���½Ρ���ͳ�ƣ���������Ƶ������վYouTubeΪ����ƽ��ÿ���Ӿ���Լ300Сʱ����Ƶ�ϴ���YouTube�ϣ�ÿ�����Ƶ�ۿ��������Ǹߴ�50�ڴΡ�������˾����Ƶ������ۿ���������Ƶ���������ࡢ�Ƽ��ȳ�����Ƶ��ؼ�������˸��ߵ�Ҫ��Ҳ�ṩ�˸�������Ӧ�ó�����
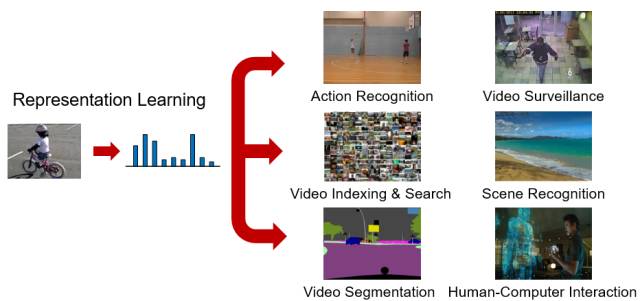
����Ƶ������ؼ����У���Ƶ��������ѧϰ��Representation Learning����һ������������⡣ѧϰ��Ƶ�����������Ǽ���������Ƶ�����ͷ����Ļ��������а�����Ƶ��ע������ʶ����Ƶ��ء���Ƶ��������Ƶ����ʶ����Ƶ�ָ��Ƶ��Ȼ���������ͻ�����Ƶ���˻������ȵȡ� Ȼ��Ŀǰ��Ƶʶ�������о�����ʹ�õ��ǻ���ͼ��ľ��������磨�����о�Ժ��2015����IJв�������ResNet����ѧϰ��Ƶ���������ַ��������ǶԵ�֡ͼ���CNN���������ںϣ�����������������ڵ�������Ƶ֡�����ϵ�Լ���Ƶ�еĶ�����Ϣ��Ŀǰ����Ƶר�õ���������绹��ȱ���� �����ھ��е�International Conference on Computer Vision ��ICCV��2017�����ϣ��������о�Ժ�����˶�ý���������ھ������µ��о��ɹ�——Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks[1]���������Ҫ������������ô�����Ƶ������ѵ����Ƶר�õ������ά���������磬�������һ�ֻ���α��ά������Pseudo-3D Convolution�����������������˼·����ʵ��������Ϊֹ�����199����ά���������硣ͨ��������ѧϰ������Ƶ����ڶ����ͬ����Ƶ����������ȡ�����ȶ������������� 
������ά�������������Ƶ������ȡ |






















��һ�ӽ�
��һ��- 2023�����Ͻ������Щ�仯 ���Ͻ�2023���������
- 2022������LPR�����Ƕ��� 1����LPRΪ3.65%��5��������LPRΪ4.3%(
- ��ط������ʵ���������ͷ�����Ѿ�������ô�죿
- �ۺ����ַ�����ͼ��б귨�͵ͼ��б귨������ۣ�
- �������ÿ�����ڣ������ÿ��Ϳ��Դ���
- ���������Щ�������ֱ�ӷŴ�5000Ԫ�Ĵ��������
- �Ŵ�ҵ��ȫ����22������
- 100%���Ӻڰ����µ�2022����ڣ����ʱ��һ��Ҫ֪��
- �������ڡ�������
- 100%���Ӻڰ����µ�2022������̣�ֵ���ղأ�
- ����ͬ���Ĵ����Ʒ��ͬһ��Ŀ���δ��
- 2023���ĸ���Ǯƽ̨������Ǯ��2020������ý�Ǯ��
- �����ؼ��Ͷ������յ����𣨶����ؼ��Ͷ������յ�������ʲô��
- 360�����������ĸ��ã�360�������˻��ǽ��±��ˣ�
- û��Ӫҵִ�տ������������û��Ӫҵִ����ô������
- Ŀǰ��Щ�����ſ���������Щ�����¿
- ������ѧ�����ѧ����ô����������ѧ�����ѧ����ô����
- ��ο��ٽ赽5000��Ǯ����ο��ٽ赽5000��Ǯ�أ�
- ֥���600����������Դ����Ǯ��ƽ̨100%�ܽ赽��
- ��������һ����ʲôԭ�������ܵĶ���
- 2023Ԫ�����ٹ�·�������?
- ���ڵ�ȡůú��Ľ�������
- ú̿�۸������ܽ�������
- ú̿�۸�Ϊʲô�ᱬ�ǣ�
- �����������һ���Լ��չ�¯��1400��1800Ԫ�ˣ������������Ǯ��
- ȫ�������բ�磬��ҵ��·���������
- ��������Ѷ�����иŻ���ETF��ģ������˭�ڳ��ף�
- �й������µ����븺��۲죬�Ƿ�����һ�������ꣿ
- �ҹ�������GDPͬ����4.9%�����������Ԥ��6%��Ŀ����
- 90����¸ڵ��ˣ����ڶ�����ʲô������
- �㶫�ֿ�ʼ���ˣ��Dz�������ҵ���ܹ�ʣ�ˣ�
- mgͨ����������¼֮��,������ô�ߣ�
- ŷ�����Ӧ������仯һ���Ӽƻ�����ҵ�������߽��ܵ���ЩӰ�죿
- ����ʿ�˺ӱ����¼�����
- ����ʿ�˺ӱ��£����ٹ�˾Ԥ�������Ǯ��
- Ϊʲô�ձ���Ϊ������ң���Ԫȴ��ô��ֵǮ��
- �Ĵ�����ͭ������ڱ���80%�������ܶ���ס��
- ��˵����������ס����10�꣬��65��Ϳ�����ȡ���ݽ����
- ����˹�����ȫ�����ҽ����
- ŷ�˸�����ũ�����˵����Ͻ�������������Ͻ������
- Ϊʲô��Щ����û�������䣿���й�����Աȥ�ķ��㣿
- Ϊʲô����ȥ�����¿��ʻ����������ϡ��Ѱ������������⣿
- ���������Ͼ����б��أ��ͻ�28�ڱ���Ѻ�����������ж��
- ˽�ºͱ���ת��һ���ڣ����л����
- ����4�����е��գ�2021�꣬��Щ���д�Ǯ���գ�
- �Ϻ����пͻ����̨����̬�Ȳ�ȡ��ǧ�����Ա�����ʧҵ��
- �������Ҳ�����
- 19��ϵͳ��Ҫ�����С�ˢ����������4000�������ȥ���ˣ�
- �����˿��Vŭ�����У�����ȡ��500���ֽ𣬷�����ʲô��
- ���������г�Ϊ�α�һߣ���ף������ij�����Ϊ��ȫ�������
- �������Ը���������Щ���
- ���������ɲ���������ˮ���������ɲ���������ˮ��
- ����Ǯ��������ȫ�ɿ�������Ǯ���Ľ��ȫ��
- ʲô����Ĵ���ƽ̨����ͨ���ģ���Щ�������ƽ̨���¿
- ���²�С��ע���˻��ܿ�ͨ�𣨻��²�С��ע���˻��ܿ�ͨ����ô��
- �ĸ�����ƽ̨��Ǯ������ͣ��ĸ�����ƽ̨��Ǯ��Ϣ��ͣ�
- ������һ��Ҫ����֤ԭ���𣨲������Dz���һ��Ҫ����֤��
- �۶��������Ĵ���ƽ̨�𣨽۶����������ƽ̨��
- ����4��5����Ϣ���𣨳���44����Ϣ�߲��ߣ�
- ����滹������Ϣ��ô�㣨����滹����Ϣ��ô����
- ��������һ��࣬û�˴���Ҳû�����ߣ�
- P2P��Ľ跽�����Բ���Ǯ����Ϊ�β���Ϊ��ʧ�š��ˣ�
- �������ȫ��ȡ�����٣������˺ͽ���ˣ���һ�������棿
- ¬־ǿ��δͶ���Ŵ��� 22������˾����أ�
- �ж���������P2P�Ŀ����ж�����Ͷ��ȥ��Ǯ�ò������ģ�
- �ֻ�hao�����ã��������������ڻ����������ô������
- ƽ̨����Э�̺�Ҫ������ֻ�����𣬲������Ż��ܵ�Ӱ����
- ��������Ǯ����Ҳ����·��
- Ƿ��һ�������������ȫ�����ڣ�Ӧ����ζȹ����ʱ�ڣ�
- �������ں��������Э��ǧ����ǩ�������Ⱳ�ӱ��뻹��֪����
- Ӱ�ӷ�������Ӧ�����˰��
- �������û�е�λ�����ÿ�
- ʲô���ڻ�ģ�⽻��
- �������У�601169����ƱͶ�ʼ�ֵ��������.docx
- Ӱ�ӹ�˾Ͷ�ʵ�Ӱ���������˰��
- �������������
- �������:��ӡ��ҵ���ñ�����Ҫ��ʲô���ϣ�
- ���ʺ�Ĺ�Ȩ������Ȩ��ֵ��μ��㣿 .pdf
- ���ʷ�Ժ�о����еĴ������Ϣ����Ρ�����������ͬ�ڴ������ʡ�
- ��˾ծȯ���������ȷ���ģ�
- 2020��˫11����
- �Ƽ�4�ſ���Ǯ�����ÿ�������Ԫ��
- 2019�����ٶȺ����ô����2019�����Ӵ�������淨����
- ������������Ǯ���ÿ��ɨһɨ����õ�����
- ֧������ë��������������������������������ʲô��
- ��ʮ�飡ʹ�������ֻ��������������㸶һ��
- ��������ë���������� ���ÿ�Ȩ��ҹ��ʲ�
- ֧����15�ں�����������������ġ���ë����
- ֧��������������֧�����������ȡ���ԣ���ɨ���������
- ֧����ɨ��֧���Ϸ�15�ڣ�֧����ɨ������ά�������ɨ����
- 2023������������ͷ��һ���������Ӵ����˽�
- �����������Щ�� 2023�궹�����һ��
- 2023����ӹ����й�˾�������ӹ����ɽ��չɼ۲�ѯ
- TOF����ɷ���_TOF��������й�˾����Щ(2/3)
- ����������Ʊ�Ĺɼ��Ƕ��٣� A�����ֳ�����Щ���й�˾��
- 3��̿��ͷ�������������Ͻ��ղ������� (2/3)
- 2023��A��VRͷ����ͷ���й�˾����Щ�� ��2 �� 5 �գ�
- 2023�������������й�˾����Щ��������������й�˾����
- ����ﯸ��������Щ������ﯸ���ɹɼ�һ����
- A��ø�Ƽ����й�˾��ͷ�ɻ��� (2023/2/5)
- �Ǹ��о��ʺû��ǵ��о��ʺã�
- Ϊʲô����ܶ���������ˣ�
- ������ţ����Ǯ�����п���Ǯ��Ϊʲô���������������
- Ϊʲô�ܶ��»���ϲ�����»���
- ��ֻETF����ʧ�ܣ�����ļ��ʧ�ܻ����̣�Ͷ��������Щ��ʧ��
- �������а������Ϊʲô�����ˣ�
- 100����������̻�������������������ѣ��ܲ�������һ���Ӳ�
- Ͷ���������ʱ�������ʲô��
- ���������ֵ��Ͷ����
- ����ı��֣����ֵ�ع���
- 2022��������Ͻ��ƶ�����ʵʩ,2022�������Ͻ������������ģ���
- ְ���籣ת����ҵ�籣�Կ�������ЩӰ�죿
- ���ϱ���ÿ�꽻9000Ԫ15���������٣���ȡ������
- ���˽���������ô������ÿ��Դ��
- ���պ��籣������ʲô����ְ���Dz��ǰ��ˣ�
- ְ���籣��ũ���籣����ͬʱ�����ĸ����㣿
- ְ���籣���˺͵�λ�ɷѱ���һ��������Щѯ��
- ����ҵҽ�Ʊ���������ô�ɷѣ���ְ��ҽ��һ����
- ���Ͻ��Ǵ�һ����6����û���������
- �����������ֱ��գ���������Щѯ�ɷ���ϸ��
- �Ϻ�����������û�Ŵ�,�Ϻ����������ſ�Ҫ���
- ��������Ը������Щ�ô���
- Ϊɶ�ҵĹ�������ɵ���ô�ߣ�
- ��������ν��ɵģ�
- ��������ܴӹ������ƶϳ�������
- ����ˣ�һ�����е�ס���������Ƿ�Ӧ����Ϊ����ͬ�Ʋ������з�
- �����ũҵ���а���ס����������
- 7���𣬹�����ӭ�����µ���������Ĺ������б仯��
- �������й�������̴���������ͬ��һ���˵����֡�һ���˴����Ƿ�
- �������й�����������ͬ����һ�������֡������Է�����ͬ�ϵ�
- ��ο�����Щ������Ҷһ�����Ԫ�ֽ���ڼ�����ˣ�
- �����������������Ƽ۲�ѯ��2021��11��12�ţ�
- �����������������Ƽ۲�ѯ��2021��11��11�ţ�
- �����������������Ƽ۲�ѯ��2021��11��9�ţ�
- usa��Ǯ���ǽ���Ԫ����������߳����ţ��ڹ����ʲô��
- �����������������Ƽ۲�ѯ��2021��11��7�ţ�
- �����������������Ƽ۲�ѯ��2021��11��6�ţ�
- �����������������Ƽ۲�ѯ��2021��11��4�ţ�
- �����������������Ƽ۲�ѯ��2021��11��2�ţ�
- �����������������Ƽ۲�ѯ��2021��11��1�ţ�
- ��24�춬�»�ͭ�Ͻ�����ԤԼΪ��û�г��֡���ɱ����
- ���Ϸ���50���ش�����������Ӱ����
- ���˴����϶�ƽ���Υ����
- �����������Ǯ��ɻƽ����������ұ�ֵ��
- �ֻ��ƽ���������������غ���ô����
- �ƽ�䵱�ͻƽ���գ����ַ�ʽ��?
- Taper�ٽ������͵�����Ϯ���ƽ����ܷ�����
- �ƽ����ڵ�������Ǯһ���ˣ�
- ��ũ���ݡ����䡱����ۺ����ֽ������������ƣ�
- 2021��10��11�Ž��ƽ�۸�������һ�ˣ�
- ��Ʒ����Ԥ��֤������Բ鵽 ��ô�����ϲ���Ʒ��Ԥ��֤
- 18��IJ۸ֲ����ļ��� 18���¥���۸ֲ����ļ���
- �·�Ԥ������֤������Բ鵽 ���ӵ�Ԥ��֤������Բ�ѯ
- ���ӹ����ȫ�İ취 ��ô��ܷ�����������
- ס����������ɱ�������ϵ� ס��������Ľɴ������������
- ����Ϊʲô�̻��ʼ������һ�� �����̻���������̻����
- ���˹������˺������↑ͨ ���˹������˻���ο�ͨ����
- 2018�Ϸ���֤�������·����� �·���ϴ�������������
- ��С��Ȩ����Ҫע��ʲô ��С��Ȩ�������������ɶ
- �µĻ�����������������Ч�� ���ڻ�������ǰ�������Լ�������
- ��������ÿ����н3000�������ȶ���С�سǣ�����������ǵϺ���
- �����ѩ���ܶ�綯�������������ˣ��綯�����ķ�չ֮·�Dz��ǻ�
- ���Ѷ�˵С�������Ժ�ᳬԽ��˹�����ڼ�������ʵ�ֵĿ�������
- ��˹��������Ӧ�����������й���Ϊʲô���Dz��ܳɣ���˹���ܳɣ�
- �����������г�����������������Σ�
- ������Ľ���������ҵ�г���ҵ��״�����ƣ�
- ��һ���һ���綯��������Ϊʲô��ô��
- Ϊʲô����ô������綯���ϰࣿ
- ������Զ���ʻ��ǰ����Σ�
- �õ���ʻ֤��������û���������������������ֵ��Ŀ���������
- 2022���ݵ������ô�շѵ� 2022���ݵ�ѼƷѱ�
- Ӣ������ȫ���ܾ�����EDGӮ�˱����������Ƕ��٣�
- 40�����ϵ����������ҹ�����ĺ�����
- Ϊʲô�о������˫ʮһ���²���������ûǮ����
- ��ý��ƽ̨���ִ�����ҽ���߿�������������ô������һ����
- ����ġ�˫11��Ϊ�Ρ������ġ���
- ����������ա���huawei�������ݣ�����ʶ����ʲô��
- ������Ǯ��ά�룬����û��Ӫҵִ����ô�죿
- �ҹ�����·ϵͳ����Щ��λ��
- �������������ˣ��ֻ���2��룬δ�����ܸĹ�������
- ���������¹�����������6+1������Ϊ���γ��е�������������ж�
- ��ɽ�����ӵĻ����ൺ�ͼ�����һ�����и����ʣ�
- ��֪�������ʡ���κ�Σ�գ�����Ϊʲô������ô���˳�ȥ�����أ�
- �����и߷��յ���ȫ���㣬��ô��ȥ�����������������������
- ��������Ӱ�ǿ�ҵ���ŵ����Ϻ���ʿ�ỹ�ǻ��ֹȣ�
- 9�����γ����¹���Ϯ����һ������ϢϢ��أ�
- 30���ˣ�����ȥ��10���Ƚϴ�ij��У����أ�
- ��������������Ա��һǧ��Ԫ���ݽ𣬿���ȥ������ʡǮ�ֺ����أ�
- �Ϻ�½�����ж����
- ������������Ӱ���ڲ⺺��145Ԫ������118Ԫ������۸�ƫ����
- �й�����GDP����2020�����а�-2020ȫ��GDPʡ������һ����
- 2020���й���������ҵ��ǿ��
- 2019��ȫ������ǧǿ�������й�����ǰ�ģ�������3120����Ԫ
- �����ֽ��ھ�ͷ����Щ��������ʮ����ھ�ͷ�������а�
- �������������������а������������ŵڶ�����һ����������
- �¹������������а¹���ҵ���еǰ�һ������־����
- �������������������а����ļ�������ã��������н�����
- ���ô������������аʼ����е�һ ��ʷ���ƾõ���������
- 2020ȫ��500ǿ�������а������� �������ǿ����һ����
- 2020����˹ȫ�����¸����������а� �ܷ���˹λ����������
- ��������ÿ����н3000�������ȶ���С�سǣ�����������ǵϺ���
- �����ѩ���ܶ�綯�������������ˣ��綯�����ķ�չ֮·�Dz��ǻ�
- ������˹60����н�����山��ҵ�Ľ�ʦ����ʦ����Խ��Խ�ھ�����
- �¶�����ĸ�ѧ������ʦ�˿�����
- ΪʲôһЩû�м��������Ĺ����������м�������������ߣ�
- ���Ѷ�˵С�������Ժ�ᳬԽ��˹�����ڼ�������ʵ�ֵĿ�������
- ��˹��������Ӧ�����������й���Ϊʲô���Dz��ܳɣ���˹���ܳɣ�
- �����������г�����������������Σ�
- ������Ľ���������ҵ�г���ҵ��״�����ƣ�
- ���Ƶϻ��г�·��
- ������˹60����н�����山��ҵ�Ľ�ʦ����ʦ����Խ��Խ�ھ�����
- �¶�����ĸ�ѧ������ʦ�˿�����
- ΪʲôһЩû�м��������Ĺ����������м�������������ߣ�
- ��˫һ������ѧ�о�����Сѧ����ʦ��ÿ�¹���2300Ԫ���Ƿ��ϧ��
- ��������������Ҫ��ò��ָܻ�������ˮƽ��
- �ҵ�һ�������Ļ�������Ҫ��ʮ��Ƿ��Ƿ�������ˣ�������
- �������˼��ڰ����������ǿ������ֵ����Ǯ��
- ���ʱ�ڣ�³Ѹÿ����300��������ҵĹ��ʣ���������Ҵ��ֵ��
- ��Ǻմ���̫�ã�������ҷݹ������Ż��ǵ��ҵ������Ϊֹ��
- Ϊʲô�кܶ���������Ǯȴ�������˵���Լ�������ˣ�